事件循环与浏览器渲染原理
#1 浏览器有哪些进程和线程
浏览器是一个多进程多线程的应用程序.浏览器启动后,会启动多个进程,其中主要的进程有:
- 浏览器的主进程:主要用来控制整个浏览器APP的生命周期,包括浏览器的UI,页面交互,地址栏,以及子进程管理等.
- 网络进程:处理和网络请求相关的任务.
- GPU进程:统一处理和图形相关的任务,例如CSS 3D,视频解码,WebGl等.
- 渲染进程:浏览器的每个标签页都会开启一个渲染进程.(
目前是,后面chrome可能会改为一个站点一个渲染进程),渲染进程启动后会开启一个渲染主线程,主要用来解析HTML,CSS,JS并渲染页面.- 渲染进程中,除了渲染主线程,还有
合成线程,光栅线程等.
- 渲染进程中,除了渲染主线程,还有
在浏览器的渲染进程中,浏览器的 渲染主线程 是最繁忙的线程,它包揽了html解析,样式计算,布局,绘制,JS执行,用户事件回调,异步回调等几乎全部阻塞型任务.
浏览器的主线程工作可以理解为浏览器需要做的一些标准流水线:
- 如果在初始状态时(
未执行到JS),那么主线程主要做的就是HTML解析,样式计算,布局,绘制等操作(详见 #3) - 如果到了JS执行阶段,此时会将所有的主线程JS代码全部执行一遍(
可以把主线程JS代码当作一个宏任务),并生成对应的队列(详见 #2). - 全部JS执行完后,此时主线程需要在屏幕刷新率(本文当做60FPS)的时间内做如下操作:
- 帧开始:获得输入事件(来源于鼠标,键盘,手势,延时等平台事件队列等宏队列[
包括延时队列,交互队列等]) - 开始执行对应的JS代码,并生成相应的队列(如果有)
- 如果有微队列,则取出并执行
- 样式计算(如果有)
- 布局(如果有)
- 生成绘制指令(如果有)
- 提交合成属性(如果有)
- 帧结束:合成线程/GPU绘制像素送显
- 帧开始:获得输入事件(来源于鼠标,键盘,手势,延时等平台事件队列等宏队列[
这就是浏览器主线程所做的事情,如果一帧里面JS代码没有执行完,导致渲染部分延后到下一帧,就会导致卡顿.
#2 事件循环(消息队列)
事件循环(Event Loop)是JS的单线程异步机制的核心. 不光是在浏览器宿主环境下,在其他环境(例如Node,Deno等)JS仍然是这种调度协议,只不过可能具体的实现形式不同. 事件循环是 任何宿主 想让它里面的 JavaScript 代码单线程又支持异步时必须实现的一套调度协议。这是JS语言模型的特性,是所有想要使用JS的宿主必须实现的协议.
为什么会产生事件循环?
由于JS的执行是在渲染主线程中,而渲染主线程又太过繁忙,要处理这么多任务,就会遇到一个难题,如何进行任务调度.例如我正在执行一个JS代码,但是此时用户点击了按钮,我该如何进行响应? 因此渲染主线程想到了一个绝妙的主意:排队
其实也不是渲染主线程想出来的,而是浏览器需要排队这样一项需求,而JS满足浏览器的需求,从而浏览器实现了JS需要的调度方法.
- 在最开始的时候,渲染主线程会进入一个无限循环状态,每次循环开始时,都会判断消息队列中是否有任务存在,如果有的话,则取出来执行;没有的话则进入休眠状态.
- 其他所有线程(包括其它进程的线程)都可以向这个消息队列中添加任务,新任务会添加到消息队列的末尾.在添加新任务时,如果此时渲染主线程是休眠状态,则会将其唤醒以继续循环拿取任务.
与事件循环紧密相连的是异步
什么是异步? 异步就是代码执行过程中遇到的无法立即处理的任务,例如定时器,XHR请求,Promise等.
如果让主线程等待这些任务执行完,那么主线程就会长期处于阻塞状态,造成卡死.
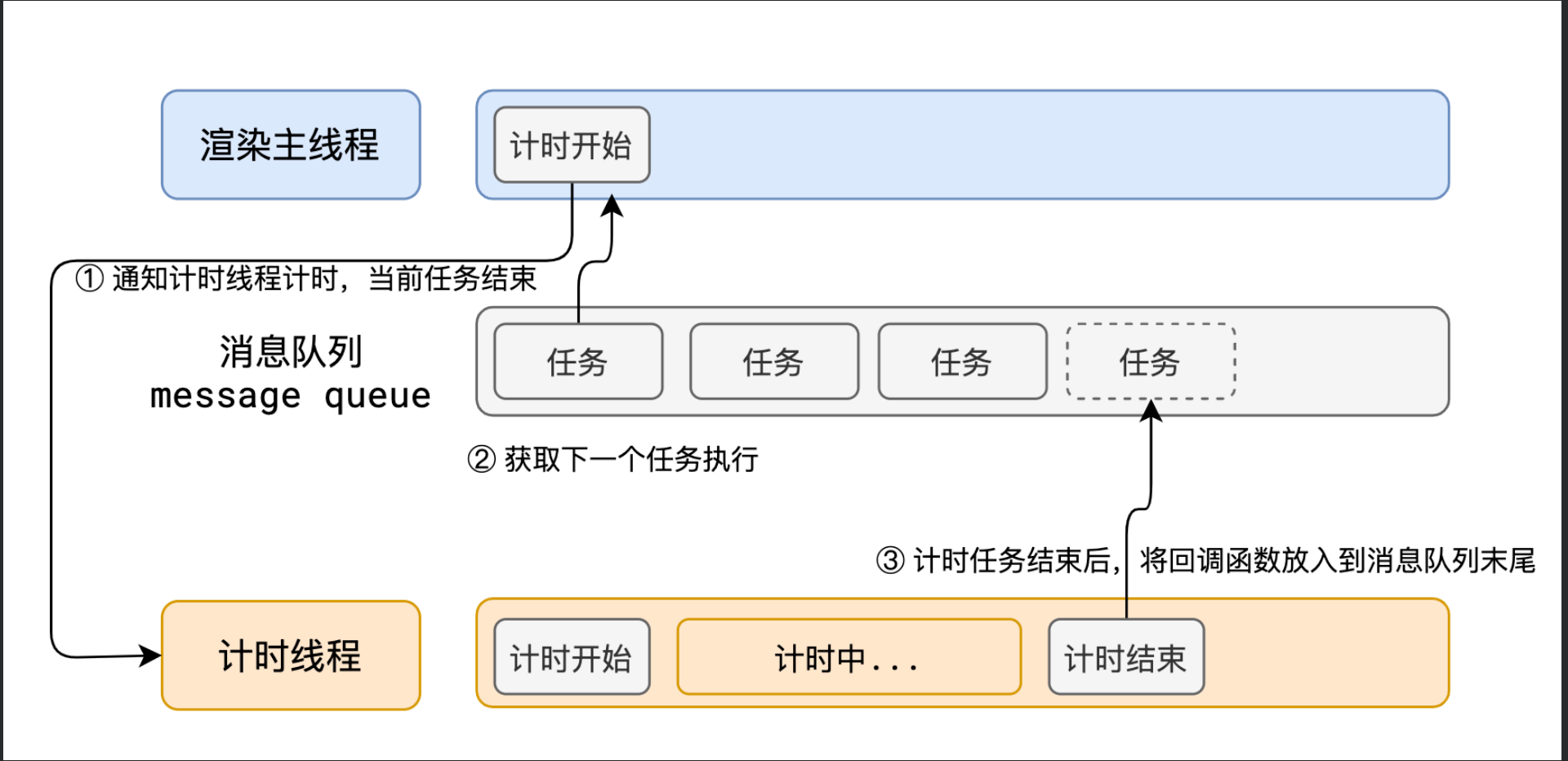
并且消息队列是有优先级的:
每个任务都有一个任务类型,同一个类型的任务必须在一个队列,不同类型的任务可以分属于不同的队列(
这将由浏览器自行控制)。 在一次事件循环中,浏览器可以根据实际情况从不同的队列中取出任务执行。
在目前 chrome 的实现中,至少包含了下面的队列:
- 延时队列:用于存放计时器到达后的回调任务,优先级「中」
- 交互队列:用于存放用户操作后产生的事件处理任务,优先级「高」
- 微队列:用户存放需要最快执行的任务,优先级「最高」 [
Promise、MutationObserver]
#3 浏览器的渲染原理
在浏览器得到一个html文档后,就会产生一个渲染任务,并将其传递给渲染主进程的消息队列。
在事件循环的作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。整个渲染流程可以分为这么几个阶段:
-
HTML 解析
-
在网络进程完成HTML文档下载后,渲染主线程就会进行HTML解析.浏览器为了提高解析效率,会先开启一个副解析器,扫描代码中是否引用CSS文件和JS文件.如果有,则会率先进行下载.
-
如果主线程解析到了
link标签,此时外部的CSS样式文件还没有下载好,主线程不会等待,而是继续向后解析.为什么主线程不需要等待CSS?
这是因为浏览器仅需要HTML文档
解析器只看标签名/属性/文本就可以确认DOM树,解析HTML文档最主要的目的就是下载关联文件与生成DOM树,而CSSOM树完全可以由样式计算阶段来负责.所以渲染主线程不会、也不需要停下来等 CSS。如果HTML解析完了,这个时候CSS还没下载完或者CSSOM还没构建完成,这个渲染主线程需要等待吗?
不会,解析仍会进行.此时页面进入
“解析完成但样式阻塞”状态,即:布局绘制被跳过,屏幕保持上一帧的内容或白屏或者纯内容画.浏览器会继续进行事件循环.一旦CSS被下载好,主线程将会在下一帧的事件循环中完成CSSOM → 样式计算 → 布局 → 绘制 → 合成. -
如果主线程解析到了普通(
不带defer,async,type=module的情况)script标签,这个时候,如果之前的CSS仍在传输/解析,则先等待前面的CSS传输/解析完成,然后执行下载好的JS代码,并将全局同步代码解析执行完成后,才会继续解析HTML.为什么HTML解析到script标签时会暂停解析?
这是因为 JS 代码的执行过程可能会修改当前的 DOM 树,所以 DOM 树的生成必须暂停。
为什么在执行JS脚本之前,需要CSS就绪?
因为脚本里可能立即读取最终计算后的样式值,浏览器必须保证读到的结果是已经应用了前面所有 CSS 规则的一致状态,否则会出现前后值不一致的竞态问题,甚至让脚本逻辑出错。这就是“CSS 阻塞脚本执行”的唯一理由。
-
在以上步骤完成之后,通常会得到一棵DOM树和CSSOM树.浏览器的默认样式、内部样式、外部样式、行内样式均会包含在 CSSOM 树中。
-
样式计算 每个元素必须保证拥有所有的CSS属性,不管是从用户代理样式表中获得还是程序员写的.否则该元素将无法正常显示.因此,如何获得每个元素的CSS的计算后的值尤为重要.样式计算主要分为以下4个步骤 => [
详见 @样式计算与视觉格式化模型] -
确定声明值
-
层叠冲突
-
使用继承
-
使用默认值
-
布局
布局会依次遍历DOM树的每一个节点,计算每个节点的几何信息.然后生成一棵布局树.
布局树和DOM树一般来说是无法一一对应的:这是因为布局树生成的时候只会生成有几何信息的DOM节点,例如display:none 就没有几何信息就不会生成到布局树上.而有一部分::before / ::after 是有几何信息的,因此会生成到布局树中.
-
分层 渲染主线程会使用一套复杂的算法来将布局树进行分层,分层的好处就是:
将来当某一个层改变后,仅会对该层进行后续处理,提升效率.滚动条、堆叠上下文、transform、opacity 等样式都会或多或少的影响分层结果,也可以通过will-change属性更大程度的影响分层结果。 -
绘制 渲染主线程会为每个层单独生成一系列绘制指令集,然后将每个图层的绘制信息提交给
合成线程,剩余工作将由合成线程来完成.合成线程会对图层进行分块,然后将块信息提交给GPU进程,让GPU完成光栅化.光栅化完成之后就是一块一块的位图了. -
画
合成线程拿到位图之后就会生成一个个的指引(quad)信息,用来表示每个位图应该画到屏幕的哪个位置,并且会考虑旋转,缩放等变形.(变形发生在合成线程里面,与渲染主线程无关,因此效率高,并且不会阻塞主线程),合成线程将quad提交给GPU进程,产生系统调用,完成屏幕成像.
#3'1 CSS真正会阻塞渲染的时机
- 在执行到JS代码前,CSSOM树还未构建成功,此时CSS会阻塞渲染.
@import会阻塞当前CSS的解析,但是不会阻塞HTML解析.- 浏览器在解析到
@import url(a.css)时:- 立即挂起当前样式表的 tokenizer
- 向网络进程发请求 a.css
- 等 a.css 下载 + 解析成 CSSOM 后,把它的规则插到当前位置
- 才继续 tokenize 当前文件里
@import之后的规则
- 浏览器在解析到
#3'2 重排与重绘
- 重绘不会修改元素的几何信息,只影响外观,此时渲染过程中会跳过 布局-分层 (渲染主线程中)步骤,直接从样式计算到达绘制步骤.
- 重排发生时是元素的几何信息被修改了,此时需要完成的过一遍渲染流程.
#3'3 为什么transform效率高
- 因为transform变形发生在合成线程,不影响渲染主线程.
#3'4 为什么对一个元素进行读取他的位置信息也会发生一次重排?
- 因为浏览器必须立即给你“当前最真实”的几何值,而它在缓存里存的是上一帧的旧值;从上次布局到你读取这一刻,JS 可能已经改了样式,所以浏览器只能当场跑一次 Layout,把新几何算出来再返回——这就是强制同步布局(forced synchronous layout),俗称“强制重排”。
- 如果只写不读,浏览器会把所有 dirty 合并到下一帧再一次性布局,此时不会强制重排.
- 强制重排是“同步、主线程、阻塞式”的——在它跑完之前,后续任何 JavaScript 都无法继续执行。
- 哪些属性会触发?
- 所有返回几何或布局信息的 API
offsetWidth/Height/Top/LeftclientWidth/HeightscrollWidth/HeightgetComputedStyle(elem).width(只要访问布局类属性)getBoundingClientRect()/getClientRects()
- 所有返回几何或布局信息的 API
#4 用户从输入URL到页面显示,中间经历了什么?
分为三个模块,客户端发送请求时,和服务端处理请求 以及 浏览器得到响应后的内部处理时。
客户端发送请求:
-
首先是浏览器的本地处理,浏览器本身的UI线程监听的keydown事件,触发比如加https前缀,或者检查url是否合法的逻辑。
-
然后就是DNS解析。对于DNS,浏览器会首先查找本机缓存,看是否有本地DNS缓存,如果有的话,则直接返回本机缓存。如果没有命中缓存,则需要递归进行DNS查询(本地 DNS → 根域名服务器(
.)→ TLD 服务器(.com)→ 权威 DNS(example.com))。返回IPV4地址并将其进行本地缓存。 -
通过DNS解析获得了IP地址后,就会建立 TCP/TLS(https) 连接,并进行三次握手[==三次握手四次挥手==] => [
详见 @网络]。此时长连接已经建立,可以进行通信。 -
然后浏览器开始构建请求报文。例如:我访问的url是https://www.baidu.com/demo。通过前面的DNS解析,我已经得到了www.baidu.com这个域名对应的IP地址了。就可以通过IP去访问对应的服务器资源。拿上述地址为例,浏览器构建的报文样式如下:
GET /demo HTTP/1.1 Host: www.example.com
服务端处理请求: 服务端根据获得的请求报文进行逻辑、资源的处理,然后构建响应报文,进行响应。
浏览器内部处理: 客户端会得到服务端返回的xxx.html文档。此时就触发了浏览器的==渲染流程== => [详见 #3]。